
DeepCubeA, l’algoritmo che risolve il cubo di Rubik
È grazie al nuovo algoritmo dell’Università della California, che un’intelligenza artificiale è riuscita a risolvere il Cubo di Rubik in soli 1,2 secondi, e nel minor numero di mosse ogni volta. Sicur...

È grazie al nuovo algoritmo dell’Università della California, che un’intelligenza artificiale è riuscita a risolvere il Cubo di Rubik in soli 1,2 secondi, e nel minor numero di mosse ogni volta. Sicuramente qualcuno starà pensando che una cosa del genere sia già stata fatta, anche in minor tempo. Ed è vero, poiché il MIT aveva creato un algoritmo di intelligenza artificiale in grado di risolvere il cubo in meno di 0.4 secondi.
La differenza sostanziale tra l’algoritmo del MIT e quello dell’Università della California, sta nel fatto che il secondo è stato sviluppato mediante una Rete Neurale, quindi simula la risoluzione del cubo così come farebbe un cervello umano, con la differenza che riesce a farlo sempre nel minor numero di mosse e sempre in circa un secondo. Scopriamo come funziona DeepCubeA.
L’Intelligenza Artificiale che impara dai propri errori
L’innovazione che sta in questo nuovo algoritmo risiede proprio nel tipo di Rete Neurale usata, e nelle tecniche di Machine Learning che adotta per risolvere l’enigma. L’IA è stata addestrata con diverse combinazioni di cubi e le è stato sempre richiesto di risolvere gli stessi nel minor tempo possibile. Grazie a questa fase di addestramento è riuscita ad “imparare” come risolvere il cubo di Rubik, sempre in modo migliore.
È proprio qui che sta la differenza con il prototipo del MIT, poiché quest’ultimo sfruttava delle combinazioni standard, dei metodi già configurati in precedenza. Erano delle combinazioni che venivano impostate in precedenza. Il prototipo dell’Università della California invece, è stato addestrato con migliaia di combinazioni diverse di cubi, e tutte sono state risolte con una media di 30 mosse massime a combinazione. La cosa più importante è che sono state risolte tutte con il 100% di successo e per il 60% dei casi, nel numero minimo di mosse possibili.
La fusione di una Rete Neurale ed un Albero di Ricerca
Questo algoritmo è sviluppato secondo due metodi, complementari tra loro. I due metodi sono rispettivamente chiamati “slow policy” e “fast policy”. Il primo riguarda l’utilizzo di una ricerca su un albero, il secondo l’utilizzo di una rete neurale. La rete neurale viene “allenata” tramite l’utilizzo dei dati generati dalla ricerca sull’albero. In questo modo i due metodi si indirizzano a vicenda per ottenere risultati sempre migliori, tramite la rete neurale, sui dati generati dalla ricerca sull’albero.
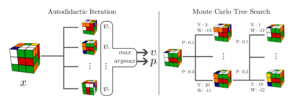
Ad ogni iterazione dell’algoritmo, gli input della rete neurale vengono creati partendo dallo stato che deve essere raggiunto (obiettivo) ed eseguendo azioni in modo casuale. Si cerca poi di dare una stima del valore ottimale per la funzione, eseguendo una prima ricerca su ciascuno stato in input ed utilizzando una ricerca in ampiezza per stimare il valore di ciascuna foglia dell’albero.
La ricerca in ampiezza (Breadth First Search o BFS) è un algoritmo utilizzato per la ricerca sui grafi. L'obiettivo principale della BFS è quello di espandere il raggio d'azione della ricerca in modo da esaminare tutti i nodi del grafo. In questo modo, partendo dal nodo detto sorgente, permette di cercare il cammino fino ad un altro nodo.
Ovviamente questo sembra un algoritmo, seppur innovativo, inutile, poiché applicato ad un banalissimo gioco, ma non è così. Questa può essere la base per la realizzazione di algoritmi sempre più performanti in termini di sicurezza, come ad esempio ha iniziato a fare Instagram, sfruttando questo tipo di algoritmi per combattere il Cyberbullismo.


